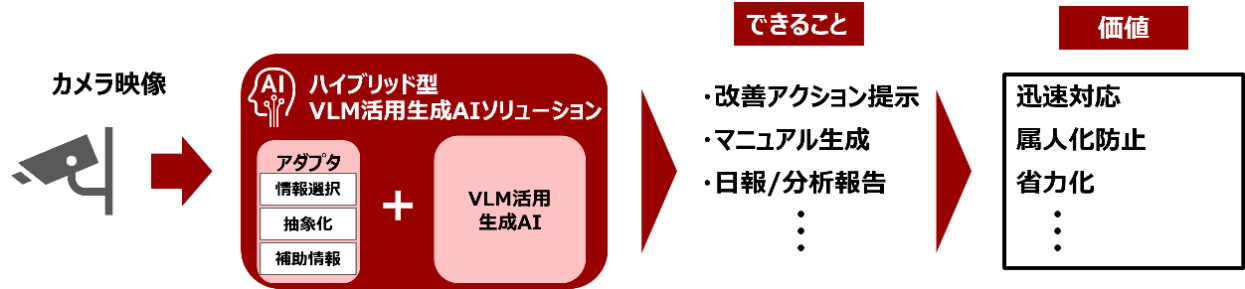
新着 速報 画像や映像などの視覚情報を理解し、 文章による説明や応答を生成できるAI 「VLM(Vision Language Model)」を活用した 実証実験を開始 2025/11/14/00:53:47 株式会社日立ソリューションズ・テクノロジーのプレスリリース:画像や映像などの視覚情報を理解し、 文章による説明や応答を生成できるAI 「VLM(Vision Language Model)」を活用した 実証実験を開始 Share via: Facebook X (Twitter) LinkedIn More Continue Reading Previous: AIを支える“銅の力” 独bedra、METAL JAPAN 2025に連続出展 日本向けバスバー供給年間2,000トンへ拡大 | bedra Vietnam Alloy Material Co., LtdNext: AI半導体が押し上げる日台協力 台湾・産業発展署が日本企業との商談15件を超え、MOU締結も進む | Smart Electronics Industry Project Promotion Office (SIPO) Related Stories TUV北德受邀亮相中国具身智能与人形机器人创新峰会,一站式赋能全品类机器人发展 新着 简体中文 TUV北德受邀亮相中国具身智能与人形机器人创新峰会,一站式赋能全品类机器人发展 2026/06/30/17:54:34 AI筑基,聚智共赢|软通动力数字基础设施服务线2026伙伴大会成功举办 新着 简体中文 AI筑基,聚智共赢|软通动力数字基础设施服务线2026伙伴大会成功举办 2026/06/30/16:54:36 IPO Perusahaan Tambang Otonom Pertama di Dunia Gaet Investor Terkemuka, Termasuk Fidelity, J.P. Morgan, dan Barings Indonesia 新着 IPO Perusahaan Tambang Otonom Pertama di Dunia Gaet Investor Terkemuka, Termasuk Fidelity, J.P. Morgan, dan Barings 2026/06/30/16:54:30