兼容数据归集、高速训练、高可用部署全场景,支持 Llama2 等千亿参数模型,读写效率提升 90%
上海 2025年6月24日 /美通社/ — 当算力狂奔时,数据存储正成为AI进化的新瓶颈。
据IDC预测:从2023年每秒产生4.2PB数据,到2028年将激增至12.5PB——AI大模型掀起的数据海啸已席卷而来。企业争相投入千亿参数模型训练,却在数据存储环节频频”触礁”:分散的原始素材难以归集、GPU集群因存储延迟空转、模型部署面临单点故障风险…传统存储方案在AI洪流中正暴露出致命短板。
痛点一:数据孤岛吞噬效率
训练素材散落于各地工作站,图像、视频、音频等非结构化数据如同碎片。传统方案依赖人工搬运,耗时易错;即便采用分布式存储,跨地域同步效率仍受制于协议兼容性。某芯片企业就曾因数据收集延迟,导致GPU集群30%时间处于闲置状态。
痛点二:存储性能扼杀算力
当千张GPU卡同时读取百万小文件时,存储延迟直接拖垮训练效率。行业常见方案中,全闪存阵列虽提速明显,但扩展性与成本难以平衡;而普通机械盘阵列的IOPS瓶颈更让AI训练寸步难行。
痛点三:部署环节暗藏风险
训练完成的百GB级模型文件,若存储系统缺乏高可用设计,一次硬件故障即可导致服务中断。某金融机构曾因存储节点宕机,线上AI客服停摆6小时损失千万。
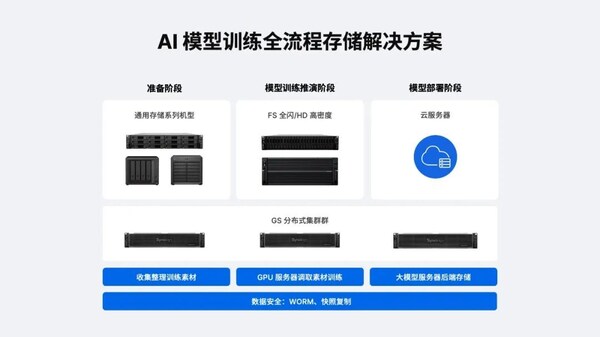
群晖 AI存储方案,破解大模型训练的”数据困局”
群晖推出AI大模型训练三级存储解决方案,直击行业痛点

/下载群晖AI模型存储方案关注群晖官微/
1)准备阶段:终结数据孤岛
- 通用存储机型(RS系列)抓取边缘设备数据,实现集中化存储和管理
- 支持SMB/NFS/iSCSI多协议,无缝对接工作站
- 华东理工大学案例:数据归集效率提升50%,释放30%磁盘空间

/下载群晖AI模型存储方案关注群晖官微/
2)训练阶段:释放算力潜能
- FS全闪系列(如FS6400)提供240,000 IOPS 4K随机写入
- HD高密度系列(如HD6500)实现单机柜PB级存储
- 对比测试:Llama2 70B模型读取时间从50分钟压缩至5分钟
3)部署阶段:护航持续服务
- GS分布式集群实现秒级故障切换,节点宕机服务零中断
- 不可变快照+WORM机制防勒索攻击
某芯片企业采用后,模型版本切换效率提升3倍!其在本地部署AI大模型的训练阶段,采用群晖全闪存存储FS6400,用于存储不断更新的大模型版本与训练数据,并通过中转站传输至推理阶段,支持模型快速切换与部署。FS6400能提供高达503,341/200,613的高速随机读写IOPS(NFS),666,419/215,353的随机读写IOPS(iSCSI)充分满足AI模型训练与实际应用阶段对高性能存储的严苛要求。
依托群晖超过20年自主研发的DSM专业存储操作系统,FS6400具备RAID硬盘冗余、快照、版本控制等多项数据保护功能,并支持整机增量备份,集高性能、高可靠性与高性价比于一体,为企业级AI应用提供坚实的数据支撑。
安全多维度保险,满足企业合规要求
群晖内置多维度的企业级安全防护,满足合规要求:Secure SignIn智能认证防范入侵,Snapshot Replication快照复制实时复制确保数据可回溯,加密存储空间满足等保要求。

/下载群晖AI模型存储方案关注群晖官微/
当AI竞赛进入深水区,存储不再只是”仓库”,而是决定训练效率的核心引擎。群晖用三级存储架构打通数据动脉,让每张GPU卡都能全速运转——毕竟在万亿参数时代,快1秒的模型迭代,可能意味着改写行业格局的钥匙。
数据革命已至,您的AI大模型存储准备好接招了吗?
超半数百强企业信赖群晖

![[MWC 2026] GlobalData、AI時代の音声進化に関するホワイトペーパーを発表](https://ai-watch.jp/wp-content/uploads/2026/03/image1-qDVxGw-300x225.jpg)